Eisuke Hirota
❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤
Dear Knowledge-Based Reinforcement Learning,What even are you? Like, what's the difference between you and Reinforcement Learning? WHAT EVEN IS "KNOWLEDGE-BASED"?? Nevertheless, all the cool kids seem to like you (e.g. Sergey Levine). So, I'd like to get to know you better.
Sincerely,
Eisuke
❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤ ❤
All jokes aside, Knowledge-Based Reinforcement Learning (KBRL) is a topic is complicated to me. That being said, I plan to focus my undergraduate research on this subject, so I hope that I can explain to the audience my current understanding of KBRL. Throughout this page, I'll go over a few main things:
- The definition of "Knowledge"
- KBRL vs (traditional) RL
- Current status
❤ Definition of KNOWLEDGE
To preface, much of the vocabulary I'll be using in this writing will come from [8], which is a journal my advisor published. Also, I may be incorrect about some things, so if that's the case, please contact me and I'll try to fix it asap!
Def. 1 (Knowledge) "We use declarative knowledge to refer to such knowledge represented as relational statements. Many methods have been developed for reasoning with declarative knowledge (RDK), often using logics." This declarative knowledge is what I'll be referring to as knowledge in this writing.
(Zhang and Sridharan, 2022)
One way to think about this is that knowledge is a truth regarding some aspect of the world. For example, the weight of an object can be considered as knowledge. Furthermore, there exists various types of knowledge, commonsense knowledge being one of them. This exists as a statement that is "humanly" sound.
Example. 1 (commonsense knowledge) "Books are usually in the library but cookbooks are in the kitchen." [8]
In terms of KBRL, much of the literature incorporates knowledge using logical reasoning. One way we can use logical reasoning is to leverage information about a certain history of state-action pairs. For example, if the state of the agent implies that our agent has not passed a certain door, then we can with certainty claim that the agent exists within a certain room. Using this outcome of the logical reasoning, we can apply it to train a policy. Thus, KBRL aims to utilize these certain truths in addition to prior RL ideas to aid an agent to discover the optimal policy more effectively.
❤ KBRL vs (traditional) RL
One question people may have is what exactly the difference is between KBRL and RL. In theory, RL should only use the reward function defined by default. KBRL takes this one step further with the addition of knowledge.
For instance, we can use knowledge to diversify rewards by formulating a task as an MDP+RM rather than a traditional MDP:
Def. 2 (Reward Machine) Given a set of propositional symbols \(P\), a set of (environment) states \(S\), and a set of actions \(A\), a reward machine \((RM)\) is a tuple \(R_{PSA}\) = \(\langle U, u_0, F, \delta_u, \delta_r \rangle\) where \(U\) is a finite set of states, \(u_0 \in U\) is an initial state, \(F\) is a finite set of terminal states (where \(U \cap F = \emptyset\)), \(\delta_u\) is the state-transition function, \( \delta_u : U\times 2^P \rightarrow U \cup F\), and \(\delta_r\) is the state-reward function, \(\delta_r: U \rightarrow [S \times A \times S \rightarrow \mathbb{R}]\).
(Icarte et al., 2022)
By implementing this additional automata, we can leverage truths of the state to incentivize certain behaviors. If the agent transitions from a certain RM state to the next, we can grant additional rewards, perhaps rewards exponentially larger than the base reward function the user created.
That being said, similar ideas already exist within traditional RL papers that don't differentiate itself from KBRL. One strong example comes from [2] in their project of using the IsaacGym simulator for training locomotion policies for quadrupedal robots:
\( \begin{array}{c c c} \hline & \text{definition} & \text{weight} \\ \text{Linear velocity tracking} & \phi (v^{*}_{b,xy} - v_{b,xy}) & 1dt \\ \text{Angular velocity tracking} & \phi (\omega^{*}_{b,z} - \omega_{b,z}) & 0.5dt \\ \text{Linear velocity penalty} & -v^2_{b,z} & 4dt \\ \text{Angular velocity penalty} & -||\omega_{b,xy}||^2 & 0.05dt \\ \text{Joint motion} & -||\ddot q_{j}||^2 -||\dot q_{j}||^2 & 0.001dt \\ \text{Joint torque} & -||\tau_{j}||^2 & 0.0002dt \\ \text{Action rate} & -||\dot q^*_{j}||^2 & 0.25dt \\ \text{Collisions} & -n_{collision} & 0.001dt \\ \text{Feet air time} & \sum^4_{f=0} (t_{air,f}-0.5) & 2dt \\ \end{array} \)
(Rudin et al., 2022)
This paper diversifies the rewards given to the agent by having a well-planned, extensive reward function. Many of these bonus rewards can be considered as knowledge. For instance, linear and angular velocity tracking considers the state of the robot at two consecutive timesteps. Furthermore, feet air time also must keep track of a history of states to determine the length of which a foot is aerial. These concepts inherintly enhance quadrupedal locomotion as the robot learns the fundamentals of what it means to walk "well".
These facts posit the question: is there really any true difference between KBRL and RL?
❤ Current Status
There isn't too much about specifically "KBRL" in the first place. Searching the key phrase "knowledge-based reinforcement learning" on Arxiv only results in 2 preprints (as of writing this blog on jan 26, 2023), and both of which are from late 2019 to early 2020. On the other hand, the phrase "reinforcement learning" + "knowledge" outputs with 1905 results (of course much of which don't relate to KBRL). Hence, it looks like KBRL is currently a phrase that the community uses to refer to the combination of RDK and RL, rather than some specifically defined terminology set in stone.
The best compilation of sources I can find regarding specifically KBRL comes from the Knowledge Based Reinforcement Learning Workshop at IJCAI-PRICAI 2020, Yokohama, Japan [3]. The conference has a five-hour long video (half of which I don't understand the material) but I'll breifly touch on the ones I like [4, 5, 6] and also understand:
(KBRL Workshop, 2022)
Reinforcement Learning with External Knowledge by using Logical Neural Networks.
This paper introduces ways to incorporate Logical Neural Networks (LNNs) with RL. The authors develop two methods: LNNs-shielding and LNNs-Guide,
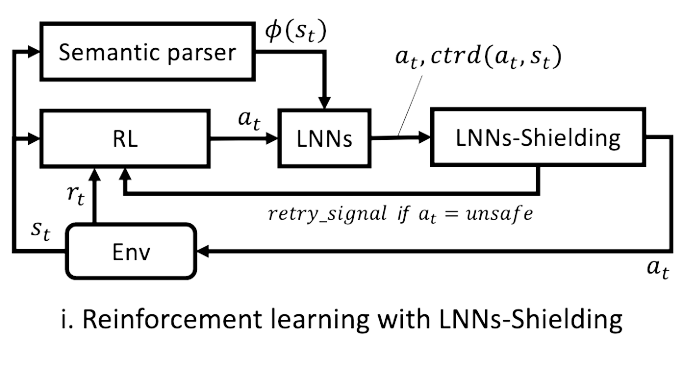
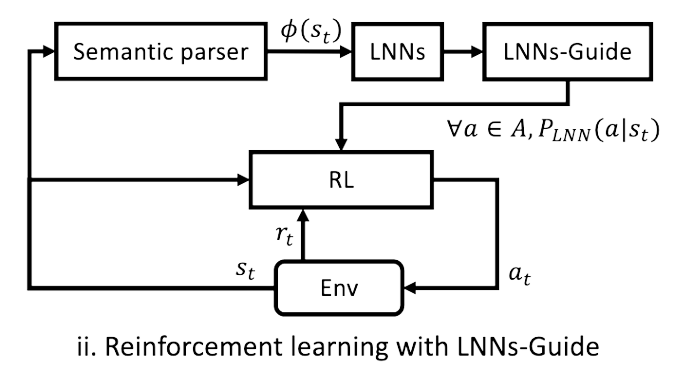
(Kimura et al., 2021)
which both aid in achieving Sample-Efficient RL. This branch of RL aims to develop policies that converge faster, combatting against the need for tremendous amounts of data that traditional RL requires (for one of the projects I work on, I had to collect almost 800 GBs of data!!). Both methods use logical reasoning to affect the actions taken by an agent. LNNs-Shielding prevents poor actions from being performed and LNNs-Guide offers recommendations to actions (which the authors observes achieves better than shielding due to the option of giving positive recommendations).
COG: Connecting New Skills to Past Experience with Offline Reinforcement Learning.
The authors of this paper aim to incorporate commonsense knowledge into RL. Through using a dataset collected in the past, they hope to develop an agent that has common sense. Their example follows such:
Example. 2 (using commonsense knowledge) Imagine a robot is in the kitchen and is tasked to cut an onion. The robot must then find a knife, so using common sense, the robot will first check any drawers.
In an implementation of traditional RL, the robot must repeat the action of opening a drawer many times to understand that it must open a drawer to potentially find a knife. The authors hope to avoid this path, given that it doesn't closely represent human behavior. What makes more sense would be for a human to have already opened a drawer in the past, and then using that past experience as common sense, apply it to the current task. The authors observe that through their method, the trained policy is able to encounter tasks and situations never seen in history before, while SOTA RL methods like SAC cannot.
Learning from Failure: Introducing Failure Ratio in Reinforcement Learning.
I like this paper becaues in my mind, it's intuitively easy to follow. The authors introduce that in a game setting (such as Chess, Go, or Othello), players may encounter a situtation where they want to undo the last move. This fundamental idea is what leads to their main novelty: the Failure Ratio.
\( \begin{array}{c} U'(s_t, a_t) = U(s_t, a_t) + \gamma^{n_{ep}}\alpha f(s_t, a_t) \\ f(s_t, a_t) = Q(s_t, a_t) - Q(s_{t+2}, a_{t+2}) \end{array} \)
(Narita and Kimura, 2022)
This novelty updates the Monte Carlo Tree Search (MCTS) algorithm used in AlphaGo [9]. Normally, the agent expands the tree by taking the maximum value predicted winning ratio which is biased by whether the agent has visited this node in the past. The failure ratio adds another bias by incentivizing the agent to also visit nodes where the expected performance is poor. Through this new layer of exploration, Narita and Kimura find that MCTS + Failure Ratio (1) performs better than vanilla MCTS in the early stages of learning the game of Othello (2) converges faster than vanilla MCTS to the optimal policy.
A Comprehensive Survey on Safe Reinforcement Learning
Lastly, I also want to briefly touch upon [7], which wasn't part of the workshop. This is an extensive report on everything related to Safe RL (as of 2015 which is when this paper was published). This paper defines two ways to approach Safe RL: (1) "transforming the optimization criterion" (2) modifiying the exploration process by the "incorporation of external knowledge and an error metric" (note. The first method inherently modifies the exploration process). We can see that through this classification, Safe RL is also a category of KBRL and uses logical reasoning to change the learning process. This branch aims to prevent the most harm caused onto the agent or the world, so it's clear how this integrates well with robotics with hopes to preserve robot parts and incentivize robots from injuring bystanders.
❤ Overview
Knowledge-Based RL exists as a branch of RL that incorporates knowledge with RL. Generally, we can see that KBRL tries to evolve RL into a more "human-like" approach. I find this concept fascinating and I think much of the AI community would find interest in such due to the goal of reaching AGI. Of course, a mere sophomore-undergrad isn't going to solve AGI, but I hope to gain more experience in these "human-like" concepts throughout my next few years, and I'll work on continuing this path during grad school!
❤ References
[1] Icarte et al. Reward Machines: Exploiting Reward Function Structure in Reinforcement Learning. 2022.[2] Rudin et al. Learning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning. 2022.
[3] KBRL Workshop. IJCAI-PRICAI. 2020.
[4] Kimura et al. Reinforcement Learning with External Knowledge by using Logical Neural Networks. 2021.
[5] Singh et al. COG: Connecting New Skills to Past Experience with Offline Reinforcement Learning. 2020.
[6] Narita and Kimura. Learning from Failure: Introducing Failure Ratio in Reinforcement Learning. 2020.
[7] García and Fernández. A Comprehensive Survey on Safe Reinforcement Learning. 2015.
[8] Zhang and Sridharan. A survey of knowledge-based sequential decision-makingunder uncertainty. 2022.
[9] Silver et al. Mastering the game of Go with deep neural networks and tree search. 2016.